
摘要:本文总结了单元测试框架JUnit的Matcher结构。
1. 引言
在Assert中存在这样一个接口:
@Test
public void testAssertThat(){
Assert.assertThat("test", org.hamcrest.CoreMatchers.equalTo("test"));
}
实际调用了:
public static <T> void assertThat(String reason, T actual,
Matcher<? super T> matcher) {
MatcherAssert.assertThat(reason, actual, matcher);
}
在MatcherAssert中的实现为:
public static <T> void assertThat(String reason, T actual, Matcher<? super T> matcher) {
if (!matcher.matches(actual)) {
Description description = new StringDescription();
description.appendText(reason)
.appendText("\nExpected: ")
.appendDescriptionOf(matcher)
.appendText("\n but: ");
matcher.describeMismatch(actual, description);
throw new AssertionError(description.toString());
}
}
我们发现这个接口并不是像assertTrue()这些接口一样直接对数据进行判定,而是调用Matcher#matches(并非正则匹配中的Matcher)进行判定,那么Matcher是个什么鬼?Matcher其实并不属于JUnit框架,而是第三方库(hamcrest)中定义的测试方式,而hamcrest也是JUnit框依赖的唯一一个第三方库。
2. Matcher家族
2.1 镇楼
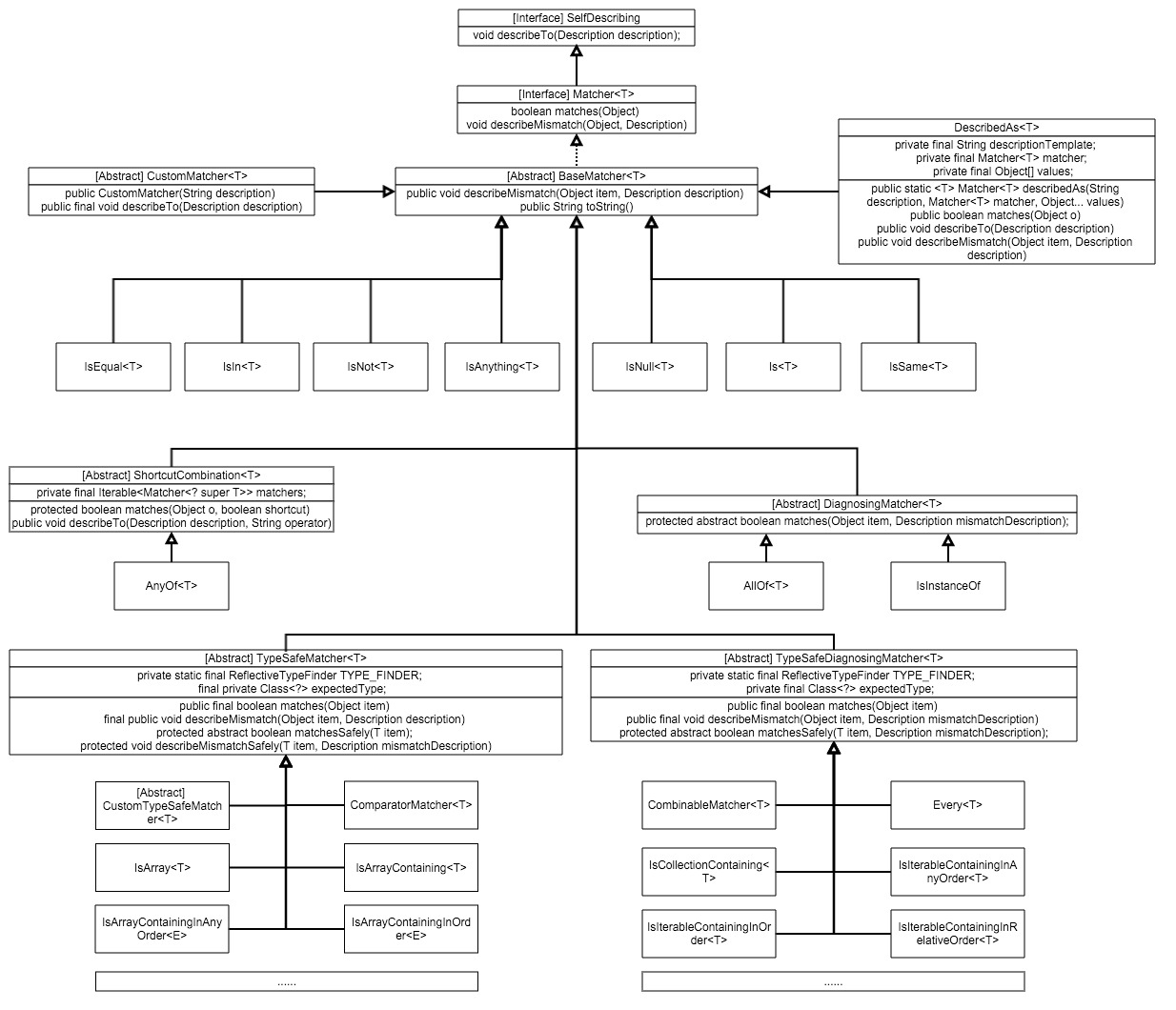
这个家族有三个传家宝 -> matches & describeTo & describeMismatch,依次分别用于匹配、描述匹配原则、说明不匹配的原因。然而老祖宗Matcher枝繁叶茂,繁衍出了一个超级家族,那么该怎么给这个族人们分支系咧?
2.2 Matcher家族之母体系
母体系的Matcher是各类Matcher的原型,包括DiagnosingMatcher、TypeSafeMatcher、TypeSafeDiagnosingMatcher、FeatureMatcher、SubstringMatcher以及CustomMatcher,CustomTypeSafeMatcher,这些类到底有哪些特性咧?下面我们一一来分析下
2.2.1 说说DiagnosingMatcher
诊断类Matcher,这类Matcher主要用于确定匹配结果,其子类需要重写以下方法:
protected abstract boolean matches(Object item, Description mismatchDescription);
而说说DiagnosingMatcher通过截断matches方法来沉默掉所有匹配时输出的信息:
public final boolean matches(Object item) {
return matches(item, Description.NONE);
}
而当需要输出匹配失败信息的时候,调用describeMismatch方法:
public final void describeMismatch(Object item, Description mismatchDescription) {
matches(item, mismatchDescription);
}
这样通过向子类传递一个非空非NONE的描述器即可输出所有匹配信息。
2.2.2 谈谈TypeSafeMatcher
这类Matcher主要附带类型检测的特技,快速拒绝空或者非指定类型的被判定对象,其子类必须复写一下方法:
protected abstract boolean matchesSafely(T item);
其中T为指定类型,被判定对象必须是该类型或其子类型的实例对象,谈谈TypeSafeMatcher通过反射该方法第一个参数的类型来确定需要判定的类型:
private static final ReflectiveTypeFinder TYPE_FINDER = new ReflectiveTypeFinder("matchesSafely", 1, 0);
this.expectedType = typeFinder.findExpectedType(getClass());
其中ReflectiveTypeFinder是一个反射指定方法中相应位置参数的类型的一个实用类,其构造函数中第一个参数为需要反射的方法,第二个参数为指定方法的参数个数,第三个参数为需要反射参数类型的位置。反射得到指定类型之后,便通过截断matches方法来实现类型判定:
public final boolean matches(Object item) {
return item != null
&& expectedType.isInstance(item)
&& matchesSafely((T) item);
}
如果类型判定通过才调用实际的判定方法matchesSafely,为了确保类型判定的完全覆盖,TypeSafeMatcher还截断了describeMismatch方法:
final public void describeMismatch(Object item, Description description) {
if (item == null) {
super.describeMismatch(null, description);
} else if (! expectedType.isInstance(item)) {
description.appendText("was a ")
.appendText(item.getClass().getName())
.appendText(" (")
.appendValue(item)
.appendText(")");
} else {
describeMismatchSafely((T)item, description);
}
}
其子类通过覆写以下方法来实现自身的不匹配描述:
protected void describeMismatchSafely(T item, Description mismatchDescription) {
super.describeMismatch(item, mismatchDescription);
}
2.2.3 该TypeSafeDiagnosingMatcher出场了
TypeSafeDiagnosingMatcher类是对DiagnosingMatcher以及TypeSafeMatcher的集成,什么意思?意思是TypeSafeDiagnosingMatcher是一个类型安全的诊断器,如果有认真看上面两种类型Matcher的实现方式,我们很容易推断出这类Matcher的是实现方式,那就是在TypeSafeMatcher的基础上改写matcheSafely方法
为带一个Description参数的方法,然后在matches方法中向子类传递一个Description.NONE,这样就可以仅做判定而不输出所有匹配信息;相应的当匹配失败需要匹配信息的时候需要传递一个非空非NONE的Description对象将信息带出。根据这个猜测我们去查看源码,发现的确是这么回事:
// 获取指定类型
private static final ReflectiveTypeFinder TYPE_FINDER = new ReflectiveTypeFinder("matchesSafely", 2, 0);
this.expectedType = typeFinder.findExpectedType(getClass());
// 要求子类重写带Description参数的matchesSafely方法
protected abstract boolean matchesSafely(T item, Description mismatchDescription);
// 在matches方法中传递一个NONE来沉默掉所有输出信息
public final boolean matches(Object item) {
return item != null
&& expectedType.isInstance(item)
&& matchesSafely((T) item, new Description.NullDescription());
}
为自己的机智点赞 ^_^
2.2.4 FeatureMatcher是个什么鬼
首先我们来看看FeatureMatcher的继承关系:
public abstract class FeatureMatcher<T, U> extends TypeSafeDiagnosingMatcher<T>
小样,来自于TypeSafeDiagnosingMatcher,那么肯定是个类型安全的诊断器,但是竟然带了两个泛型类型,T类型比较好解释,那么U类型是用来干嘛的,隐隐觉得已经触碰到类Matcher的灵魂了,宝贝儿不要挣扎了,让我看到你的内心:
protected abstract U featureValueOf(T actual);
要求所有子类复写featureValueOf方法,根据T类型返回U类型,有点函数编程的意思,哈!查看源码发现这个返回值实际是在match的时候使用的:
protected boolean matchesSafely(T actual, Description mismatch) {
final U featureValue = featureValueOf(actual);
if (!subMatcher.matches(featureValue)) {
mismatch.appendText(featureName).appendText(" ");
subMatcher.describeMismatch(featureValue, mismatch);
return false;
}
return true;
}
原来实际判定的并不是T类型,而是通过T类型返回的U类型特征值,这也就是这类Matcher的特征了。
2.2.5 看看SubstringMatcher
SubstringMatcher的继承关系:
public abstract class SubstringMatcher extends TypeSafeMatcher<String>
哦~~是一个类型安全的子串匹配器,它要求子类复写方法:
protected abstract boolean evalSubstringOf(String string);
这个方法判断是否以特定的方式包含指定子串,从matchesSafely可以看出来:
public boolean matchesSafely(String item) {
return evalSubstringOf(ignoringCase ? item.toLowerCase() :item);
}
SubstringMatcher还有一个特殊的字段用于确定是否是大小写无关的判定:
private final boolean ignoringCase;
protected String converted(String arg) {
return ignoringCase ? arg.toLowerCase() : arg;
}
而其子类在重写evalSubstringOf方法的时候必须调用converted方法对指定字符串以及传入字符串进行转换。
2.2.6 最后说说鸡肋的用户自定义Matcher原型
// 基于BaseMatcher创建自定义Matcher
public abstract class CustomMatcher<T> extends BaseMatcher<T>
// 基于TypeSafeMatcher创建自定义Matcher
public abstract class CustomTypeSafeMatcher<T> extends TypeSafeMatcher<T>
说它们鸡肋是因为如果真的要设计用户自定义Matcher的时候,一般不太会从这两个类进行继承,- -!
2.3 Matcher家族之基础系
这一系家族成员的特征是:直接判定出匹配结果。为了更好地说明,我们以IsEqual<T>为例:
public class IsEqual<T> extends BaseMatcher<T>
IsEqual继承自BaseMatcher,其构造函数:
public IsEqual(T equalArg)
要求必须传递一个判定标准,即被判定的对象必须与这里传入的对象相等方可通过测试,判定方式为:
public boolean matches(Object actualValue) {
return areEqual(actualValue, expectedValue);
}
private static boolean areEqual(Object actual, Object expected) {
if (actual == null) {
return expected == null;
}
if (expected != null && isArray(actual)) {
return isArray(expected) && areArraysEqual(actual, expected);
}
return actual.equals(expected);
}
这里对基本对象直接调用equlas方法进行判定,而对于对象数组则需要采用Deep Equal的方式进行判定,这里我们看到matches方法是可以直接得出判定出结果,而不需要借助于其他Matcher成员,这也是根基系家族成员的基本特征:直接判定出匹配结果。族系成员还包括:
// 匹配所有对象,直接返回true
public class IsAnything<T> extends BaseMatcher<T>
// 判断被判定对象是否包含在设定的集合内
public class IsIn<T> extends BaseMatcher<T>
// 判断被判定对象是否为Null
public class IsNull<T> extends BaseMatcher<T>
// 判断被判定对象是否跟设定对象完全一样(==)
public class IsSame<T> extends BaseMatcher<T>
// 是否是指定类型
public class IsInstanceOf extends DiagnosingMatcher<Object>
// 特定size的array
public class IsArrayWithSize<E> extends FeatureMatcher<E[], Integer>
// 特定size的Collection
public class IsCollectionWithSize<E> extends FeatureMatcher<Collection<? extends E>, Integer>
// 特定size的Iteratable
public class IsIterableWithSize<E> extends FeatureMatcher<Iterable<E>, Integer>
// 特定size的Map
public final class IsMapWithSize<K, V> extends FeatureMatcher<Map<? extends K, ? extends V>, Integer>
// 继承或等于指定事件且事件源一致
public class IsEventFrom extends TypeSafeDiagnosingMatcher<EventObject>
// 与指定BigDecimal接近
public class BigDecimalCloseTo extends TypeSafeMatcher<BigDecimal>
// 采用指定Comparator计算与指定对象之间的比较值在某个范围之内
private static final class ComparatorMatcher<T> extends TypeSafeMatcher<T>
// 空白字符串
public final class IsBlankString extends TypeSafeMatcher<String>
// 与指定浮点数的在指定误差之内
public class IsCloseTo extends TypeSafeMatcher<Double>
// 继承指定类或与指定类一致
public class IsCompatibleType<T> extends TypeSafeMatcher<Class<?>>
// 空集合
public class IsEmptyCollection<E> extends TypeSafeMatcher<Collection<? extends E>>
// 空迭代器
public class IsEmptyIterable<E> extends TypeSafeMatcher<Iterable<? extends E>>
// 空字符串
public final class IsEmptyString extends TypeSafeMatcher<String>
// 大小写无关equal
public class IsEqualIgnoringCase extends TypeSafeMatcher<String>
// 去除多余空白字符之后大小写无关equal
public class IsEqualIgnoringWhiteSpace extends TypeSafeMatcher<String>
// Double.isNaN
public final class IsNaN extends TypeSafeMatcher<Double>
// 可被指定正则表达式匹配
public class MatchesPattern extends TypeSafeMatcher<String>
// 按指定顺序包含指定所有子串
public class StringContainsInOrder extends TypeSafeMatcher<String>
// 包含子串
public class StringContains extends SubstringMatcher
// 以特定子串结束
public class StringEndsWith extends SubstringMatcher
// 以特定子串开始
public class StringStartsWith extends SubstringMatcher
看完这一串基本判定,我的内心是崩溃的!
2.4 Matcher家族之复合系
复合系的Matcher们比较聪明,它们不愿意干那些直接判定的“脏活累活”,而是通过资源整合来利用已有的基础Matcher做一些上层设计,让用户能更好更清晰的设计自己的匹配逻辑。下面就让我们掀开他们的盖头来:
2.4.1 最简单的Is
public boolean matches(Object arg) {
return matcher.matches(arg);
}
就是判定指定matcher是否能匹配传入对象,简单的无言以对,一定是我打开的姿势不对,翻来看去也就只剩下这三个static方法了:
public static <T> Matcher<T> is(Matcher<T> matcher) {
return new Is<T>(matcher);
}
public static <T> Matcher<T> is(T value) {
return is(equalTo(value));
}
public static <T> Matcher<T> isA(Class<T> type) {
final Matcher<T> typeMatcher = instanceOf(type);
return is(typeMatcher);
}
简单得想哭,我有一个梦想,那就是世界上所有的代码都这么简单 - -!既然如此简单,就顺带看了IsNot<T>,然后,然后就没有然后了,大家照着字面理解就行了。
2.4.2 AllOf
public class AllOf<T> extends DiagnosingMatcher<T>
嗯,是一个诊断器,看起来应该有点干货:
private final Iterable<Matcher<? super T>> matchers;
public boolean matches(Object o, Description mismatch) {
for (Matcher<? super T> matcher : matchers) {
if (!matcher.matches(o)) {
mismatch.appendDescriptionOf(matcher).appendText(" ");
matcher.describeMismatch(o, mismatch);
return false;
}
}
return true;
}
oh, NO!师傅你就给我看这个吗?不解释了。我只想说,看官们,到这里我只想告诉大伙,勇敢地去研究源码吧,一个模块一个模块的看,其实并不难。另外既然又说到DiagnosingMatcher,那么我就吐槽一下这里的一个设计上的小细节,大家有没发现诊断器会在matches中调用一次诊断,然后在输出不匹配信息的时候又调用了一次诊断,这两次诊断没有缓存结果,所以不得不诊断两次,我认为这是赤裸裸的浪费cpu,难道仅仅因为我是个测试用例就不考虑我的效率了吗?有谁能告诉我这里面有更重要的设计意图?
2.4.3 AnyOf
public class AnyOf<T> extends ShortcutCombination<T>
public boolean matches(Object o) {
return matches(o, true);
}
在AnyOf<T>中并没有实现matches(Object, boolean),唯一的解释是在ShortcutCombination中实现的:
private final Iterable<Matcher<? super T>> matchers;
protected boolean matches(Object o, boolean shortcut) {
for (Matcher<? super T> matcher : matchers) {
if (matcher.matches(o) == shortcut) {
return shortcut;
}
}
return !shortcut;
}
ShortcutCombination的设计应该是为了能够扩展出“任何不匹配”的子类,但在这有限的利用用途上,个人认为没必要抽像出一个中间层,又多加载了一个Class不是 - -!
2.4.4 IsArray
private final Matcher<? super T>[] elementMatchers;
public boolean matchesSafely(T[] array) {
if (array.length != elementMatchers.length) return false;
for (int i = 0; i < array.length; i++) {
if (!elementMatchers[i].matches(array[i])) return false;
}
return true;
}
需要指定Matcher数组与传入对象数组按Index依次匹配。
2.4.5 IsArrayContaining
public boolean matchesSafely(T[] array) {
for (T item : array) {
if (elementMatcher.matches(item)) {
return true;
}
}
return false;
}
判定传入数组中是否含有与指定Matcher匹配的对象。
2.4.6 IsArrayContainingInAnyOrder
private final IsIterableContainingInAnyOrder<E> iterableMatcher;
private final Collection<Matcher<? super E>> matchers;
public boolean matchesSafely(E[] item) {
return iterableMatcher.matches(Arrays.asList(item));
}
从matchesSafely中可以发现匹配的核心在于IsIterableContainingInAnyOrder,我们来看下:
private final Collection<Matcher<? super T>> matchers;
protected boolean matchesSafely(Iterable<? extends T> items, Description mismatchDescription) {
final Matching<T> matching = new Matching<T>(matchers, mismatchDescription);
for (T item : items) {
if (! matching.matches(item)) {
return false;
}
}
return matching.isFinished(items);
}
实际的判定是通过Matching来实现的,源码就不放上来了,原理上是对传入可遍历对象中的每一个对象遍历指定matchers集合找到一个可匹配的Matcher并移除,若找不到则返回fasle,如果传入的所有对象均能找到可匹配的Matcher,则在最后判定matchers集合是否为空(用于判定最初matchers集合的size是否与传入对象数一致),如果为空则表示IsIterableContainingInAnyOrder匹配成功。
2.4.7 IsArrayContainingInOrder
private final Collection<Matcher<? super E>> matchers;
private final IsIterableContainingInOrder<E> iterableMatcher;
public boolean matchesSafely(E[] item) {
return iterableMatcher.matches(asList(item));
}
赤裸裸的指向了IsIterableContainingInOrder<E>:
private final List<Matcher<? super E>> matchers;
protected boolean matchesSafely(Iterable<? extends E> iterable, Description mismatchDescription) {
final MatchSeries<E> matchSeries = new MatchSeries<E>(matchers, mismatchDescription);
for (E item : iterable) {
if (!matchSeries.matches(item)) {
return false;
}
}
return matchSeries.isFinished();
}
其中MatchSeries执行了顺序匹配,即在顺序遍历被判定对象集合的时候,找到matchers中对应序号的Matcher进行匹配,匹配成功则进入下一轮匹配,匹配失败则直接返回false;当遍历结束之后判断matchers中所有Matcher是否被匹配,若还有未匹配Matcher则说明被判定对象集合的size与matchers的size不等,返回false;以上所有条件满足返回true。
2.4.8 IsIterableContainingInRelativeOrder
protected boolean matchesSafely(Iterable<? extends E> iterable, Description mismatchDescription) {
MatchSeriesInRelativeOrder<E> matchSeriesInRelativeOrder = new MatchSeriesInRelativeOrder<E>(matchers, mismatchDescription);
matchSeriesInRelativeOrder.processItems(iterable);
return matchSeriesInRelativeOrder.isFinished();
}
而MatchSeriesInRelativeOrder执行匹配逻辑:遍历被判定对象集合,找到一个与matchers中当前序号最小的未匹配Matcher的被判定对象,标记该Matcher为已匹配后进行下一轮遍历,知道所有Matcher已匹配或者被判定对象遍历完成,最后matchers中若仍有未匹配对象则返回false,否则返回true。
2.4.9 IsMapContaining<K,V>
private final Matcher<? super K> keyMatcher;
private final Matcher<? super V> valueMatcher;
public boolean matchesSafely(Map<? extends K, ? extends V> map) {
for (Entry<? extends K, ? extends V> entry : map.entrySet()) {
if (keyMatcher.matches(entry.getKey()) && valueMatcher.matches(entry.getValue())) {
return true;
}
}
return false;
}
在被判定Map中找到一个key与keyMatcher匹配且value与valueMatcher匹配的元素。
2.4.10 StacktracePrintingMatcher
java
private final Matcher<T> throwableMatcher;
protected boolean matchesSafely(T item) {
return throwableMatcher.matches(item);
}
与指定Matcher匹配,这并不是重点,重点是在不匹配的时候输出Throwable的stackTrace:
java
protected void describeMismatchSafely(T item, Description description) {
throwableMatcher.describeMismatch(item, description);
description.appendText("\nStacktrace was: ");
description.appendText(readStacktrace(item));
}
因此这个类可用于忽略已知的指定Throwable,而抛出那些未知的以及关注的Throwable的详细异常栈信息。
2.4.11 ThrowableCauseMatcher
private final Matcher<? extends Throwable> causeMatcher;
protected boolean matchesSafely(T item) {
return causeMatcher.matches(item.getCause());
}
Throwable的Cause与指定Matcher相匹配。
2.4.12 ThrowableMessageMatcher
private final Matcher<String> matcher;
protected boolean matchesSafely(T item) {
return matcher.matches(item.getMessage());
}
Throwable的Message与指定Matcher相匹配。
2.5 Matcher家族之服务系
目前看起来这一系只有一根独苗DescribedAs<T>:
private final Matcher<T> matcher;
public boolean matches(Object o) {
return matcher.matches(o);
}
public void describeMismatch(Object item, Description description) {
matcher.describeMismatch(item, description);
}
其matches及describeMismatch方法均直接转给被其包装的Matcher对象,这些都不是重点,重点是对describeTo做了处理,支持参数化描述:
private final String descriptionTemplate;
private final Object[] values;
private final static Pattern ARG_PATTERN = Pattern.compile("%([0-9]+)");
public void describeTo(Description description) {
java.util.regex.Matcher arg = ARG_PATTERN.matcher(descriptionTemplate);
int textStart = 0;
while (arg.find()) {
description.appendText(descriptionTemplate.substring(textStart, arg.start()));
description.appendValue(values[parseInt(arg.group(1))]);
textStart = arg.end();
}
if (textStart < descriptionTemplate.length()) {
description.appendText(descriptionTemplate.substring(textStart));
}
}
从指定模板中找出“%+参数序号”的参数位置用相应参数替换,实现参数化描述。
3. Description
其实到这里已经可以结束Matcher的分析了,但是为了更完整,我决定把Description这最后一块处女地也放进来:
public interface Description {
static final Description NONE = new NullDescription();
Description appendText(String text);
Description appendDescriptionOf(SelfDescribing value);
Description appendValue(Object value);
<T> Description appendValueList(String start, String separator, String end,
T... values);
<T> Description appendValueList(String start, String separator, String end,
Iterable<T> values);
Description appendList(String start, String separator, String end,
Iterable<? extends SelfDescribing> values);
Description 中所有方法都类似于生成器中的方法,可用于链式编程。其目前含有两个常用子类:NullDescription及StringDescription:其中NullDescription重写所有方法均什么都不做仅返回this,从而实现吞没所有描述;我们主要分析下StringDescription:
public class StringDescription extends BaseDescription{
private final Appendable out;
@Override
protected void append(String str) {
try {
out.append(str);
} catch (IOException e) {
throw new RuntimeException("Could not write description", e);
}
}
@Override
protected void append(char c) {
try {
out.append(c);
} catch (IOException e) {
throw new RuntimeException("Could not write description", e);
}
}
}
采用一个Appendable将字符及字符串描述附加到该Description对象中,并且我们发现StringDescription继承自BaseDescription,所以还需要感受下BaseDescription:
先来看两个基本方法:
protected void append(String str) {
for (int i = 0; i < str.length(); i++) {
append(str.charAt(i));
}
}
protected abstract void append(char c);
要求子类必须重写append(char),同时子类也可以重写append(String)以实现效率提升,子类中的这两个基本方法主要决定数据应该输出到哪里,是其他所有方法实现的基础。接下来我们来看两个上层的方法:
public Description appendValue(Object value) {
if (value == null) {
append("null");
} else if (value instanceof String) {
toJavaSyntax((String) value);
} else if (value instanceof Character) {
append('"');
toJavaSyntax((Character) value);
append('"');
} else if (value instanceof Short) {
append('<');
append(descriptionOf(value));
append("s>");
} else if (value instanceof Long) {
append('<');
append(descriptionOf(value));
append("L>");
} else if (value instanceof Float) {
append('<');
append(descriptionOf(value));
append("F>");
} else if (value.getClass().isArray()) {
appendValueList("[",", ","]", new ArrayIterator(value));
} else {
append('<');
append(descriptionOf(value));
append('>');
}
return this;
}
这个方法将所有类型转换成有识别性的字符串。
private Description appendList(String start, String separator, String end, Iterator<? extends SelfDescribing> i) {
boolean separate = false;
append(start);
while (i.hasNext()) {
if (separate) append(separator);
appendDescriptionOf(i.next());
separate = true;
}
append(end);
return this;
}
这个方法采用一个统一的接口转换数组为可读性比较好的字符串。
